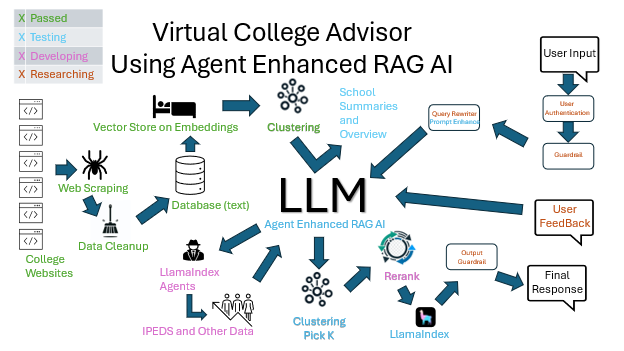
My Virtual College Advisor, an agent-enhanced RAG AI system, is on course for its debut this summer. The product aims to find a great college fit for applicants while providing colleges with capable students. This system will allow applicants to chat as they would with ChatGPT, but focused on answering questions about schools and directing applicants to relevant pages on school websites. It is also being built for under $1,000 in initial costs with a target of $100 a month in technology processing costs to run.
I apologize upfront that this post will be highly technical. In future posts, I’ll talk more about the capabilities of this product, how the user interface works, and provide some sample interactions. However, for this post, I wanted to focus on the more technical aspects. Unlike a simple RAG AI, such as loading a lot of research PDFs into a RAG for searches, which is fairly straightforward, a RAG AI like this presents quite different challenges due to the scale and the greater breadth of likely queries.
Learning, Speed, Accuracy, Low Cost – The Major Considerations
“Above all, it has to work.” -Daniel Bernstein
My main focus has been on understanding what will work to the quality and scale I need. This RAG AI pulls from over a million web pages and thousands of pieces of publicly available data and has to be responsive to hundreds or thousands of concurrent users. So, I can’t just take pieces off the shelf and assume they’ll work fine together. Every piece has to be rigorously tested to ensure it will perform at scale.
Once I have a product that works at scale, I can try other solutions to see if they might work better or just as well but for a lower cost. For now, while cost certainly matters, making sure everything works as needed is the primary task. After all, it doesn’t matter how fast or cheap it is if it doesn’t provide the answers the customer needs.
The secondary task is learning. While I am building this product with the express purpose of marketing it, and I expect it to do well, it is also a way for me to deeply explore the latest in RAG AI technology. I have given many large presentations about AI, been on panels, hosted advisory boards about its uses, and delved deep into the concerns and regulations around it. I have written frequently about AI topics big and small. But being a food critic is wildly different from being a chef, and I yearned to be back in the weeds.
As such, learning as much as I can by actually doing was a major goal. Having built hundreds of products, I also know that there’s a world of difference between a true production-ready project and one that a single developer runs locally for a single purpose. This is why executives can wonder why it will take three people six months to build a system that took a month to build in Excel. Code control, redundancy, backups, user authentication, and security are just a few of the things a production product has to deal with that an Excel file does not.
The challenge with a RAG AI, especially using multiple agents, is to make it both fast and accurate. Modern users won’t sit around for five minutes waiting for a website to give them an answer. There’s also the speed of development to consider. And then, there’s cost.
For instance, at one point, I calculated that my screen scraping of 5,500 college websites would take over four months with my desktop running continuously. Besides making it tough to get a product out in a timely manner, this was running on my desktop. Not having my desktop fully available was unacceptable, so I moved the scraping to the cloud. I also kept researching scraping until I found a new tool, Spider-rs, which scrapes significantly faster and handles more scenarios than the basic scraper I built did. My legion of AWS servers using this new faster technique handled the scraping in under a week.
Overall Choices
LlamaIndex: My first major decision, and a good one, was to build all of this using LlamaIndex. The beauty of LlamaIndex is how easily it integrates with different LLMs, data sources, rerankers, embedders, and other tools needed for LLM development. The ability to try different pieces and mix and match them without having to rewrite large parts of the system is a critical advantage. I would strongly recommend LlamaIndex to anyone working with LLMs. Given my debt to those who created it, and since I created some new pieces I needed for my own work, I have started contributing to LlamaIndex. So far, I have contributed a reader, but I have several other additions to add as time allows.
OpenAI: For all AI-specific processing, including rerankers, embeddings, agents, and the LLM itself, I use OpenAI, preferably through LlamaIndex. I had a strong temptation to use cheaper HuggingFace models or explore offerings by other major providers such as Gemini or Grok, but ultimately, OpenAI is well documented and has solid performance and good APIs. Given LlamaIndex’s flexibility, I can easily switch later if I find a better option.
AWS: I chose AWS to host my database and my ‘legion’ of servers for the wrong reason. I chose it because I haven’t used it much before. In the past, I’ve used Azure, which I quite like. I figured this was a good excuse to learn the basics of AWS and see what the differences are. Since AWS is the market leader, it seemed like some familiarity with it would be a good thing. AWS has been a fine choice, but I think going with Azure would have been fine as well. Hosting services are more commoditized than I had realized.
Python: For a programming language, I chose Python. The choice seemed simple; most samples for LlamaIndex are in Python, and almost everything works with Python these days, so it was a safe choice. I have used many computer languages; everything from R to Go to C++. I’ve even had to do a bit of COBOL, FORTRAN, and PL/1. At one point, I was a true expert in Mumps, a RISC language, now known mostly as the backend of the EPIC system. I hadn’t used Python much, but I’ve done enough coding that picking up the basics was one of the lesser learning curves of this journey. It’s a nice language, and I enjoy coding in it. So far, the only thing I’ve found that really sets it apart is the vast number of libraries connected to it and easy to find and work with.
Data
A fast and accurate solution begins with high-quality data. The data I am collecting is primarily from school websites, and these sites are pretty heterogeneous. So, the data must be:
- Collected
- Cleaned carefully, with duplicates removed
- Purged of extraneous data which could cause noise
- Stored (so that I can have the LLM point right to the base URL)
- Embedded
In addition, the agents need data from a structured database, which I’ll discuss below.
Proof of Concept: Text Files
I started by saving the scraped results to text files, each scraped page having its own file. The great advantage of this is observability, being able to easily see what data came in. Another advantage is that LlamaIndex’s Simple Reader makes using text files as a basis for a RAG AI simple, literally just two lines of code. This allowed me to do basic testing with a few web pages as RAG input. Combining those with sample queries allowed me to test from the start whether I would likely be able to accomplish my goals.
My first trials were less than promising. Even with a simple query and web pages I knew the content of, the results were inaccurate and incomplete. I had battled a similar issue when I built The Journey Sage Finder, a small RAG AI app that pulled all of the YouTube videos for an influencer, transcribed them, allowed users to ask a chatbot questions about the videos, and be sent to exactly the point in each video where the topic was discussed.
The answer in the Journey Sage Finder was mostly refining the prompt to return better answers. While the lessons I learned about prompting were indeed important here, they did not work for these school web pages. Moreover, I was only using a few hundred web pages, and this method was too slow and cumbersome to scale to what would eventually be over a million web pages.
The problem turned out to be noise in the data. Because I was scraping websites, each page had menus, headers, footers, and massive amounts of styling. I was using Beautiful Soup to remove the styling, but I had naively thought the menus, headers, and footers should be kept as they contain valuable information. The problem, which seems obvious in hindsight, is that these items were repeated in each and every file, resulting in massive redundancy. Moreover, those items not only don’t meaningfully contribute to the semantic meaning of the page, but when encoded, they pull the value away from the actual meaning of the page. In short, they are just noise.
Once I cleaned out the noise, queries started to be answered quickly and correctly. At this point, I knew that this project could work. I also knew that building it at scale would be the challenge.
Scaling Data
Once I proved the concept, I needed to start thinking about where to house these websites. While easy to work with, text files would ultimately be too slow and would, at the very least, require external indexing and an external vector store. The least expensive way to handle them would be to use an open-source database and run it on my high-end desktop. This has several obvious downsides, not the least of which is that it restricts my own usage of my main machine in ways I didn’t want to deal with.
I felt I needed to have the original content around and quickly searchable, not just the embeddings, for a few reasons:
- As a root backup in case I needed to change anything with the embeddings later. The scraping process is no small task, and I didn’t want to repeat it.
- So I could look at the raw content for verification.
- In case later, I would implement word or hybrid searches.
I did a lot of looking at different options. I focused on ElasticSearch because I had some previous experience with it. I also looked closely at Pinecone because of its strong reputation as a vector database. Ultimately, I chose MongoDB because it’s easy to connect to, fairly inexpensive, and it appeared that with its Atlas Vector Search, I might be able to keep all of my data together while getting the speed I needed. Since it is cloud-based, I could easily connect from anywhere.
Moreover, I’ve been careful to abstract layers, which LlamaIndex helps with, so that nothing in the app is overly tied to any specific resource, be it database or LLM. Meaning that I could move the data later if needed.
Unsurprisingly, basic testing on MongoDB Vector Index Search shows a high correlation between time taken and the number of candidates in a vector search. This test was done with a database of about a million documents with 100 candidates and a limit of 100 or the number of candidates, whichever is less. For those unfamiliar, this is similar to going into a library with a million books and asking the librarian to bring you the 1,000 books closest to your topic. Once those arrive, you ask them to sort through them and give you the 100 most relevant.
Note: The low times with high page searches are directly related to caching.

Currently, I’m exploring different alternatives to Mongo Atlas Vector Search and comparing them for their timing. Milvus looks especially promising, with an initial pass being about three times faster than Atlas Vector Search, but off of a far smaller base of documents. As is typical with RAGs, the results from this search are less than stellar at exact results. In terms of the librarian metaphor above, the 100 books returned are on topic, but what the librarian says are the top picks of those 100 are not the best picks. As such, a reranker is needed.
Reranking
While the vector search quickly gets a number of good possible candidates based on a semantic comparison of the query and the embeddings in the database, the reranker takes a slower but more accurate angle. This allows for a good combination of a quick first pass with a more measured second pass.
LLMRerank: For my reranking, I’ve started with LlamaIndex LLMRerank. With it, I am using OpenAI’s GPT-3.5 Turbo to look at all the selected documents and reorder them to how well they match the query. The downside of using an LLM reranker is that it’s much, much slower than other methods. Currently, this is taking a half second per item in the list to be reranked.
On the flip side, LLMRerank produces high-quality output. I have yet to run an objective evaluation on it, but the answers are clearly of high quality, unlike the answers without the reranker.
Agents
Agents, essentially functions built into the chat so the LLM can call outside itself to get specific information, have so far been amazingly quick and easy to implement. The use for agents in this product is to get hard data about specific schools that the LLM would not otherwise know. For instance, I have all of the SAT and ACT scores for all colleges and universities that accept them.
As soon as a user says what their scores are, the agent goes and uses them to see which schools they are more or less likely to be accepted to based on those scores. This then informs all further conversations, as the system then knows not to talk as much about schools the applicant has little chance of getting into.
Agents have also been built to pull:
- School religious affiliation (if any)
- ZIP code and address info, including distance from the applicant
- Type of school (for instance, Professional vs. Academic)
- Tuition based on residency
This agent implementation is straightforward using LlamaIndex’s OpenAI Agent. This is still in the early testing phase, but so far seems to work well while being almost as simple as writing a few functions. I’ve put enough new technologies together to be wary of declaring victory with the agents yet. No doubt there will be interesting things that I have to overcome, making for an interesting future post.
What’s Next
I have only scratched the surface of what I’ve learned, and yet this blog post that was targeted to be a thousand words is nearing 3,000. I see that I will need many further posts to fill out the details, but I hope what I have shared has been helpful. Here are some items that warrant their own future posts:
Evaluation: I’ve talked a lot about how “it must work” correctly, but not so much about how I will know if it’s working. Apart from some speed charts, I have not shared anything objective about its functioning. That is because the evaluation process is not complete and ever-changing, but once the product is “in production,” having an automated and repeatable evaluation process to ensure that queries are returned quickly and accurately will be essential. This will also allow for easier evaluation of other lower-cost components.
Guardrails: Implementing a RAG AI without guardrails would be like setting up a network without a firewall, prone to issues. I will almost certainly use NeMo Guardrails from NVIDIA when I reach that point in the project.
DevOps: One regret I have is not setting up a full DevOps process from the very beginning. This is all the more embarrassing as I am good friends with Andrew Clay Shafer, who is sometimes credited with coining the term DevOps. While I do have some basics built in, I do not have formatters, linters, or anything of the sort set up. The entire point of Continuous Integration (CI) and Continuous Delivery (CD) is that integration is always more work than expected, and by being built in from the start, it minimizes the future pains of pulling it all together. But knowing you should do something and actually doing it are two different things! It should make an interesting blog post detailing my struggles when I do implement it.
Conclusion
In conclusion, My Virtual College Advisor represents a significant advancement in the application of RAG AI systems, specifically tailored to the educational sector. By integrating LlamaIndex for modularity, OpenAI’s robust models for processing, LlamaIndex Agents for increased accuracy, and AWS for scalable infrastructure, we are creating a system that is not only efficient but also highly adaptable.
Technical Innovations:
- Advanced Data Processing: Utilizing cutting-edge web scraping techniques and data cleaning processes, we ensure high-quality, relevant data.
- Scalable Architecture: By leveraging a vector store on embeddings and sophisticated clustering algorithms, our system will be able handle over a million web pages and support thousands of concurrent users.
- Reranking for Precision: Implementing a dual-layered approach with vector searches followed by LLM reranking ensures users receive the most relevant and accurate information swiftly.
Performance Metrics:
- Scraping Efficiency: Our use of Spider-rs and AWS infrastructure reduced the scraping time from four months to under a week.
- Query Response Time: Initial tests show a high correlation between query complexity and response time, with optimizations in place to handle peak loads efficiently.
- Accuracy: The integration of LLMRerank has significantly improved the quality of responses, with subjective evaluations indicating a marked improvement over baseline models.
Community Engagement:
We invite feedback and collaboration from the AI community to further refine and enhance My Virtual College Advisor. Contributions to LlamaIndex and the exploration of alternative vector databases like Milvus are ongoing efforts that could benefit from community insights. Moreover, the implementation of guardrails and a comprehensive DevOps process are areas where shared knowledge and experience would be invaluable.
As I continue to develop this system, I look forward to sharing more detailed insights and technical evaluations in future posts. Thank you for your interest and support in this innovative project. Together, we can shape the future of AI in education.
Leave a Reply